Введение
Бывают дни, когда на работе делать нечего. А бывают дни, когда ты — программист и звукорежиссёр одновременно, и в голову приходит странная мысль: «А что, если взять аудио, превратить его в картинку-спектрограмму, сжать эту картинку как фотографию (JPEG, WebP, AVIF), а потом попробовать восстановить звук обратно? Как оно будет звучать?»
Спойлер: иногда — удивительно хорошо. Иногда — как из унитаза. Но всегда — интересно.
В этой статье я расскажу, как реализовал весь этот пайплайн, покажу код, проведу батч-тесты разных форматов и уровней качества, и, конечно, дам послушать результаты. Все исходники прилагаются, и вы сможете повторить эксперимент сами.
Идея
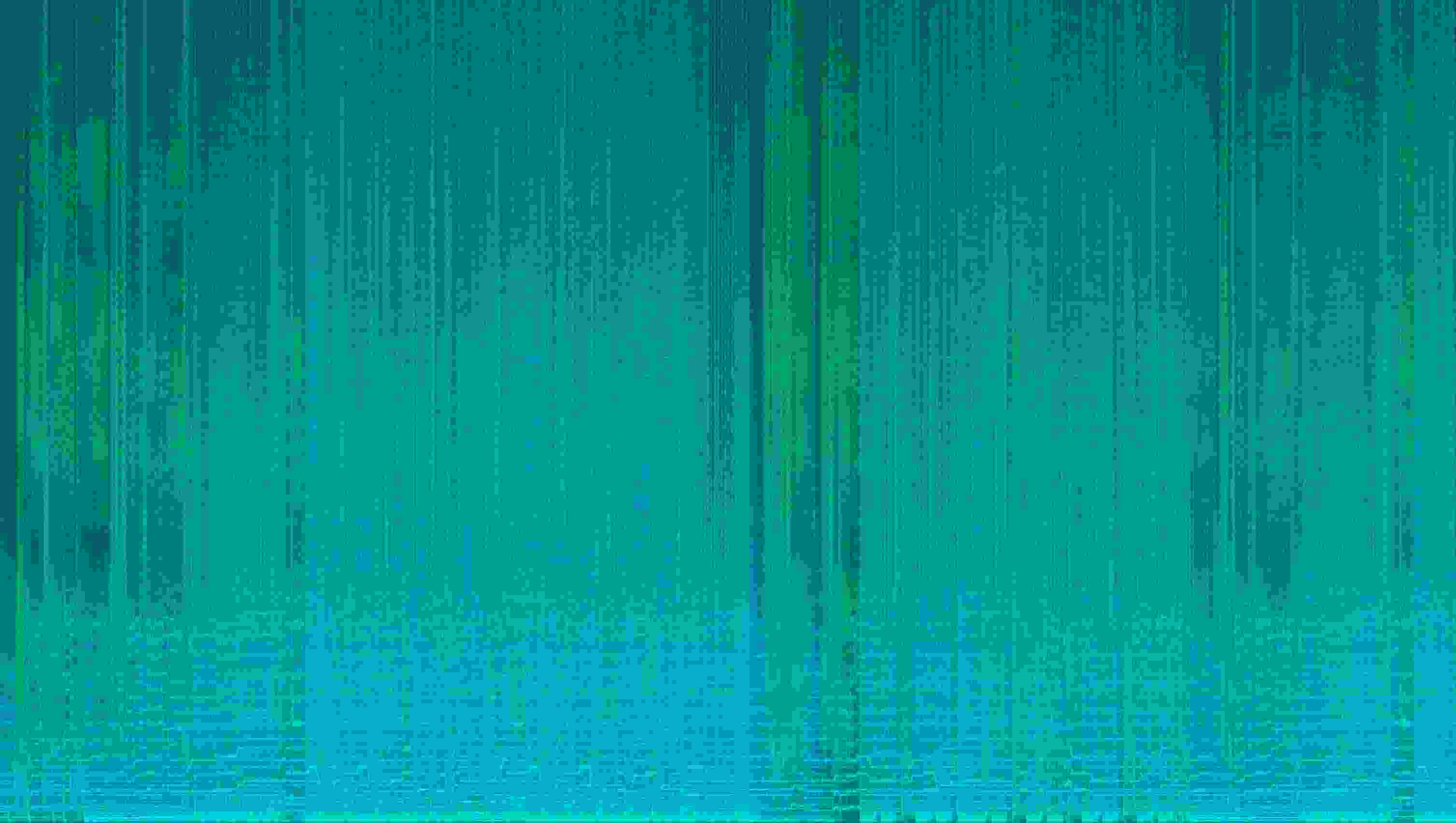
Спектрограмма — это визуальное представление звука: по горизонтали — время, по вертикали — частота, цвет — амплитуда. Если сохранить спектрограмму как картинку, а потом сжать её с потерями (как JPEG), то при восстановлении звука обратно мы получим... артефакты сжатия, но уже в аудио! Именно это я и хотел услышать.
Для стерео я использовал Mid/Side представление:
- Зелёный канал (G) — Mid (моно-сумма левого и правого)
- Синий канал (B) — Side (разница между левым и правым)
- Красный канал (R) — не используется (пока)
Амплитуды логарифмируются в децибелы и маппятся в диапазон 0–255 (8 бит на канал). Частоты выше порога автоматически обрезаются для экономии места. Затем картинка сохраняется в нужном формате.
При декодировании фаза восстанавливается через алгоритм Гриффина-Лима (Griffin-Lim), потому что в спектрограмме мы храним только амплитуду, а фаза теряется.
Важное замечание о формате аудио
Прежде чем мы перейдём к деталям — один технический момент. Все восстановленные WAV-файлы я, разумеется, не выкладываю как есть. Во-первых, это было бы жестоко по отношению к серверу (70 секунд стерео 44.1/16 — это ~12 мегабайт на каждый тест, а тестов у нас 18). Во-вторых, это просто бессмысленно — WAV нужен только как промежуточный формат при обработке.
Все аудиопримеры, которые вы услышите, упакованы в Opus 128 kbps. Это современный, исключительно эффективный кодек, который на битрейте 128 kbps обеспечивает прозрачное качество — то есть WAV и Opus на этих настройках звучат абсолютно идентично для человеческого уха, но файл весит в 10 раз меньше. Так что вы не теряете ровным счётом ничего в качестве прослушивания, а сервер скажет вам спасибо.
Для интересующихся: Opus — это open-source кодек от IETF (RFC 6716), используемый в YouTube, WhatsApp, Discord и WebRTC. На битрейте 128 kbps для стерео он работает в гибридном режиме: нижние частоты кодируются линейным SILK-кодеком, верхние — MDCT на основе CELT. Проще говоря — это лучшее, что есть в lossy audio на сегодня.
Архитектура проекта
Проект состоит из нескольких модулей:
config.py — пресеты FFT и дефолтные настройки
encoder.py — аудио → изображение
decoder.py — изображение → аудио
phase_generator.py — алгоритм Гриффина-Лима для восстановления фазы
transforms.py — Mid/Side ↔ Left/Right преобразования
utils.py — утилиты (JSON, размеры файлов, очистка)
main.py — одиночный прогон пайплайна
test_runner.py — батч-тестирование форматов сжатия
Основной пайплайн (main.py)
Полный цикл выглядит так:
def full_pipeline(config: dict):
"""Полный цикл: аудио -> изображение -> аудио (с генерацией фазы)."""
preset = PRESETS[config["active_preset"]]
n_fft = preset["N_FFT"]
hop_length = preset["HOP_LENGTH"]
# Шаг 1: MP3 -> WAV
wav_temp = Path(data_dir) / "temp_stereo.wav"
mp3_to_wav(config["mp3_file"], str(wav_temp))
# Шаг 2: WAV -> изображение
image_path = str(Path(data_dir) / f"spectrogram.{ext}")
metadata, _ = audio_to_image(wav_temp, image_path, n_fft, hop_length, config)
# Шаг 3: изображение -> WAV
recovered_path = str(Path(data_dir) / "recovered.wav")
audio_recovered = image_to_audio(image_path, recovered_path, metadata)
return audio_recovered
Кодирование в изображение (encoder.py)
Ключевой фрагмент — преобразование аудио в RGB-картинку:
def audio_to_image(wav_path, image_path, n_fft, hop_length, config):
y, sr = librosa.load(wav_path, sr=44100, mono=False)
# Mid/Side преобразование
mid = (y[0] + y[1]) * 0.5
side = (y[0] - y[1]) * 0.5
# STFT
D_mid = librosa.stft(mid, n_fft=n_fft, hop_length=hop_length, window='hann')
D_side = librosa.stft(side, n_fft=n_fft, hop_length=hop_length, window='hann')
# В децибелы и в 0..255
mag_mid_db = librosa.amplitude_to_db(np.abs(D_mid), ref=np.max)
mag_mid_norm = np.clip((mag_mid_db - mag_min) / (-mag_min) * 255, 0, 255).astype(np.uint8)
# RGB: G=Mid, B=Side, R=0
rgb = np.zeros((n_freqs, n_frames, 3), dtype=np.uint8)
rgb[:, :, 1] = mag_mid_norm # Зелёный = Mid
rgb[:, :, 2] = mag_side_norm # Синий = Side
img = Image.fromarray(np.flipud(rgb), 'RGB')
# ... сохранение через PIL с параметрами качества
Автоматический срез высоких частот — экономим место, отбрасывая то, что всё равно не слышно:
def _find_high_cut_auto(mag_mid_db, mag_side_db, freqs, threshold_db=-80, freq_min=8000):
mean_mag = np.maximum(np.mean(mag_mid_db, axis=1), np.mean(mag_side_db, axis=1))
# Сглаживание и поиск первого стабильного падения ниже порога
below_threshold = mean_mag_smooth < effective_threshold
for i in range(min_idx, len(freqs) - 5):
if np.all(below_threshold[i:i+5]):
return freqs[i], i
Декодирование и восстановление фазы (decoder.py + phase_generator.py)
Самая сложная часть — восстановление утерянной фазы:
def image_to_audio(image_path, output_wav_path, metadata):
img = Image.open(image_path).convert('RGB')
arr = np.array(img, dtype=np.float32)
# Достаём Mid и Side из зелёного и синего каналов
mag_mid_norm = arr[:, :, 1] / 255.0 # Зелёный
mag_side_norm = arr[:, :, 2] / 255.0 # Синий
# Обратно из dB в амплитуду
mag_mid = librosa.db_to_amplitude(mag_mid_db, ref=ref_mid)
# Генерация фазы через Griffin-Lim (fast, parallel)
phase_mid, phase_side = griffin_lim_stereo_parallel(
mag_mid, mag_side, n_fft, hop_length,
iterations=5000, mode='fast'
)
# Восстановление комплексного спектра и обратное STFT
D_mid = mag_mid * np.exp(1j * phase_mid)
y_mid = librosa.istft(D_mid, hop_length=hop_length, window='hann')
# Mid/Side -> Left/Right
left = mid + side
right = mid - side
return np.stack([left, right], axis=1)
Алгоритм Гриффина-Лима (fast-версия с memory layout оптимизациями):
def griffin_lim_fast(magnitude, n_fft, hop_length, iterations=50, ...):
rng = np.random.RandomState(random_seed)
angles = rng.uniform(-np.pi, np.pi, magnitude.shape).astype(np.float32)
for i in range(iterations):
# Собираем комплексный спектр с текущей фазой
stft_matrix = magnitude * np.exp(1j * angles)
# ISTFT -> STFT для получения новой оценки фазы
y = librosa.istft(stft_matrix, hop_length=hop_length)
D_new = librosa.stft(y, n_fft=n_fft, hop_length=hop_length)
angles = np.angle(D_new)
# Early stopping
if improvement < early_stop_threshold:
patience_counter += 1
if patience_counter >= early_stop_patience:
return best_angles
return angles
Тестирование форматов сжатия (test_runner.py)
Я написал автотестер, который для каждого формата и уровня качества:
- Конвертирует MP3 → WAV
- Кодирует в изображение
- Декодирует обратно в WAV
- Считает размер файла и время
Результаты сохраняются в отдельные папки с отчётами. Вот конфигурации тестов:
TEST_CONFIGS = {
"png_max": {"output_format": "png", "output_quality": 9, "output_lossless": True},
"jpeg_q100": {"output_format": "jpeg", "output_quality": 100},
"jpeg_q75": {"output_format": "jpeg", "output_quality": 75},
"jpeg_q50": {"output_format": "jpeg", "output_quality": 50},
"jpeg_q25": {"output_format": "jpeg", "output_quality": 25},
"jpeg_q5": {"output_format": "jpeg", "output_quality": 5},
"webp_q100": {"output_format": "webp", "output_quality": 100},
# ... и так далее для WebP и AVIF
}
Результаты тестов
Важное замечание: SNR в этих тестах не показателен, потому что восстановленный сигнал сдвинут по фазе относительно оригинала — пики могут не совпадать, хотя звучит всё приемлемо. Поэтому оценивать качество лучше на слух (аудиопримеры приложены к статье для каждого теста).
| Тест | Размер (MB) | Время кодирования (сек) | Время декодирования (сек) | Файлы |
|---|---|---|---|---|
| PNG (lossless) | 8.47 | 1.9 | 299.4 | spectrogram.png / recovered.opus |
| WebP lossless | 6.62 | 13.2 | 294.2 | spectrogram.webp / recovered.opus |
| WebP q100 | 3.16 | 2.8 | 185.5 | spectrogram.webp / recovered.opus |
| WebP q75 | 0.66 | 1.7 | 170.0 | spectrogram.webp / recovered.opus |
| WebP q50 | 0.35 | 1.4 | 164.3 | spectrogram.webp / recovered.opus |
| WebP q25 | 0.16 | 1.2 | 162.5 | spectrogram.webp / recovered.opus |
| WebP q5 | 0.05 | 1.0 | 176.7 | spectrogram.webp / recovered.opus |
| JPEG q100 | 4.57 | 1.1 | 205.7 | spectrogram.jpg / recovered.opus |
| JPEG q75 | 0.76 | 0.5 | 158.9 | spectrogram.jpg / recovered.opus |
| JPEG q50 | 0.45 | 0.5 | 139.3 | spectrogram.jpg / recovered.opus |
| JPEG q25 | 0.22 | 0.5 | 162.3 | spectrogram.jpg / recovered.opus |
| JPEG q5 | 0.04 | 0.5 | 203.5 | spectrogram.jpg / recovered.opus |
| AVIF lossless | 4.06 | 21.1 | 194.3 | spectrogram.avif / recovered.opus |
| AVIF q100 | 4.06 | 20.9 | 188.1 | spectrogram.avif / recovered.opus |
| AVIF q75 | 1.27 | 40.4 | 164.0 | spectrogram.avif / recovered.opus |
| AVIF q50 | 0.28 | 30.8 | 157.9 | spectrogram.avif / recovered.opus |
| AVIF q25 | 0.02 | 11.6 | 171.1 | spectrogram.avif / recovered.opus |
| AVIF q5 | 0.004 | 5.1 | 176.1 | spectrogram.avif / recovered.opus |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Исходный MP3: 44.4 MB (264 сек, обработанный фрагмент — 70 сек)
Размер восстановленного WAV (70 сек стерео 44.1/16): ~12.1 MB
Аудиопримеры выложены в Opus 128 kbps: ~1.1 MB каждый
Анализ
PNG и lossless-форматы. PNG (8.47 MB) и WebP lossless (6.62 MB) — самые большие, но это честное сжатие без потерь. Интересно, что WebP lossless сжал лучше PNG — примерно на 22%. При этом PNG кодируется быстрее всех — 1.9 секунды против 13.2 у WebP lossless.
Lossy-сжатие: экстремальные значения. Самый маленький файл — AVIF q5 (4 KB!). На 70 секунд стерео-аудио! WebP q5 выдал 51 KB, JPEG q5 — 43 KB. Это сжатие в ~1000 раз относительно WAV и в ~250 раз относительно MP3 исходного качества. Четыре килобайта на минуту с лишним звука — с ума сойти.
Скорость кодирования. JPEG — абсолютный чемпион: 0.5 секунды на любое качество. AVIF, наоборот, самый медленный — до 40 секунд на высоком качестве. Оно и понятно: AVIF использует значительно более сложный кодек (внутри — AV1), который делает намного больше вычислений для достижения такой плотности сжатия.
Скорость декодирования. Время декодирования почти одинаковое (~160–200 сек), так как основное время съедает алгоритм Гриффина-Лима (до 5000 итераций), а не чтение картинки. JPEG чуть медленнее из-за характерных блочных артефактов — алгоритму требуется больше итераций, чтобы «сгладить» их.
Интересные наблюдения:
WebP q100 (3.16 MB) и AVIF q100 (4.06 MB) дают заметно больший размер, чем JPEG q75 (0.76 MB), но звучат... по-разному — - JPEG добавляет характерный «звон», а WebP и AVIF артефачат более «гладко»
- AVIF lossless и AVIF q100 дали одинаковый размер (4.06 MB) — видимо, на этих данных кодер решил, что q100 эквивалентен lossless
- WebP q5 показал парадоксально неплохое звучание при 51 KB — для голосовых записок или подкастов может быть интересно
- JPEG q5 (43 KB) звучит откровенно плохо, но слова разобрать можно — блочная структура JPEG даёт характерное «квакающее» эхо на высоких
Как это звучит?
К статье приложены файлы spectrogram. и recovered.opus* для каждого теста (напоминаю: аудио в Opus 128 kbps, потому что WAV бессмысленно гонять через интернет). Вот некоторые субъективные впечатления:
- PNG/WebP lossless: как оригинал, но с характерной «шероховатостью» от Гриффина-Лима — лёгкий фазовый шум, к которому быстро привыкаешь. Это baseline, лучше чего уже не сделать без сохранения фазы.
- JPEG q75: удивительно достойно, лёгкое «звенящее» послезвучие на высоких, но музыка остаётся музыкой
- JPEG q50: заметное «жужжание» и потеря деталей в верхах, середина ещё терпима
- JPEG q5: звук как из консервной банки, переданный по факсу, но слова разобрать можно — характерный блочный артефакт 8×8 пикселей превращается в ритмичный треск на высоких
- WebP q5: на удивление чище, чем JPEG на тех же битрейтах — WebP артефачит более «гладко», без резких блочных границ
- AVIF q5 (4 KB!): шум, треск, артефакты — но факт, что это вообще работает, поражает. Звук отдалённо напоминает оригинал, как будто слушаешь через трубу в ветреную погоду
Как повторить самому
- Клонируйте исходники (ссылка в конце статьи)
- Установите зависимости:
pip install numpy librosa soundfile Pillow pydub scipy
- Для AVIF поддержки может понадобиться:
pip install pillow-avif-plugin
# или
pip install pillow-heif
- Положите MP3-файл в папку проекта и назовите track.mp3 (или измените путь в config.py)
- Запустите одиночный тест:
python main.py
Результаты появятся в папке data/: спектрограмма и восстановленный WAV.
- Запустите батч-тестирование всех форматов:
python test_runner.py
Создаст папку test_results_[timestamp]/ с отдельными подпапками для каждого теста. В каждой — spectrogram, recovered.wav, metadata.json и report.txt. Общий сводный отчёт будет в summary_report.txt.
- Настройте пресеты и качество в config.py — там всё задокументировано:
PRESETS = {
"75p_n4096": {"N_FFT": 4096, "HOP_LENGTH": 1024}, # 75% overlap
"87p_n4096": {"N_FFT": 4096, "HOP_LENGTH": 512}, # 87.5% overlap
# ...
}
DEFAULT_CONFIG = {
"mp3_file": "track.mp3",
"trim_start": 60.0, # Начало фрагмента в секундах
"trim_end": 130.0, # Конец (0 = до конца)
"phase_generate_iterations": 5000,
"griffin_lim_mode": "fast",
# ...
}
Заключение
Этот эксперимент показал, что современные форматы сжатия изображений, особенно AVIF и WebP, могут фантастически эффективно упаковывать спектрограммы. Мы говорим о сжатии в сотни и тысячи раз — 70 секунд стерео-аудио в 4 килобайтах. Да, с артефактами, но само то, что это возможно — впечатляет.
Практического смысла в этом, конечно, маловато (MP3 и Opus справляются с аудиосжатием куда лучше, потому что заточены именно под особенности человеческого слуха). Но как эксперимент на стыке двух областей — аудио и изображений — это было чертовски интересно. И теперь я знаю, как звучит JPEG.
К статье приложены:
- Исходники проекта (config.py, encoder.py, decoder.py, phase_generator.py, transforms.py, utils.py, main.py, test_runner.py)
- Для каждого теста: spectrogram.* + recovered.opus (128 kbps) + metadata.json + report.txt
- Сводный отчёт summary_report.txt
Все исходники распространяются свободно — делайте что хотите. Если натренируете нейросеть «слышать» JPEG-артефакты — дайте знать :)
Комментарии (0)
Оставить комментарий
Пока нет комментариев. Будьте первым!